
🔥 React Query와 React Context
React Query의 가장 큰 장점 중 하나는 컴포넌트 트리의 어느 곳에서나 쿼리를 사용할 수 있다는 점입니다. 예를 들어 <ProductTable> 컴포넌트는 필요한 곳에서 직접 데이터를 가져올 수 있습니다:
function ProductTable() {
const productQuery = useProductQuery()
if (productQuery.data) {
return <table>...</table>
}
if (productQuery.isError) {
return <ErrorMessage error={productQuery.error} />
}
return <SkeletonLoader />
}
function ProductTable() {
const productQuery = useProductQuery()
if (productQuery.data) {
return <table>...</table>
}
if (productQuery.isError) {
return <ErrorMessage error={productQuery.error} />
}
return <SkeletonLoader />
}
이 방식은 ProductTable을 독립적이고 자급자족할 수 있게 만듭니다. 이 컴포넌트는 자신의 의존성인 제품 데이터를 직접 관리합니다. 캐시에 데이터가 이미 있다면 좋고, 없다면 새로 가져옵니다. 이런 패턴은 React 서버 컴포넌트에서도 비슷하게 나타납니다. 서버 컴포넌트 역시 컴포넌트 내부에서 직접 데이터를 가져올 수 있게 해줍니다. 더 이상 '상태가 있는' 컴포넌트와 '상태가 없는' 컴포넌트, 또는 '스마트한' 컴포넌트와 '멍청한' 컴포넌트 사이의 인위적인 구분이 필요 없어집니다.
컴포넌트 내부에서 직접 데이터를 가져오는 것은 매우 유용합니다. ProductTable 컴포넌트를 앱의 어느 곳으로 옮기더라도 잘 작동할 것입니다. 이 컴포넌트는 '변화에 강하다'고 할 수 있습니다. 이것이 바로 제가 #10: 상태 관리자로서의 React Query와 #21: React Query로 생각하기에서 필요한 곳에서 직접 쿼리에 접근하는 방식(보통 커스텀 훅을 통해)을 권장하는 주된 이유입니다.
하지만 이 방식이 만능은 아닙니다. 모든 것이 그렇듯 이 방식에도 장단점이 있습니다. 그렇다면 우리가 여기서 무엇을 얻고 무엇을 잃는 걸까요?
독립적인 컴포넌트
컴포넌트가 자급자족하려면 쿼리 데이터를 사용할 수 없는 상황, 특히 로딩 상태와 에러 상태를 처리할 수 있어야 합니다. <ProductTable> 컴포넌트의 경우 처음 로드될 때 <SkeletonLoader />를 보여주는 것이 큰 문제가 되지 않습니다.
하지만 쿼리의 일부 정보만 필요하고, 컴포넌트 트리의 상위에서 이미 쿼리가 사용되었다는 것을 '알고 있는' 상황도 많이 있습니다. 예를 들어 로그인한 사용자의 정보를 담고 있는 userQuery가 있다고 가정해 봅시다:
export const useUserQuery = (id: number) => {
return useQuery({
queryKey: ['user', id],
queryFn: () => fetchUserById(id),
})
}
export const useCurrentUserQuery = () => {
const id = useCurrentUserId()
return useUserQuery(id)
}
export const useUserQuery = (id: number) => {
return useQuery({
queryKey: ['user', id],
queryFn: () => fetchUserById(id),
})
}
export const useCurrentUserQuery = () => {
const id = useCurrentUserId()
return useUserQuery(id)
}
이 쿼리는 컴포넌트 트리의 초반에 사용되어 로그인한 사용자의 권한을 확인하고, 페이지를 볼 수 있는지 결정하는 데 쓰일 것입니다. 이는 페이지 전체에서 필요한 핵심 정보입니다.
이제 트리 아래쪽에 userName을 표시하는 컴포넌트가 있다고 가정해 봅시다. 이 컴포넌트는 useCurrentUserQuery 훅에서 정보를 가져올 수 있습니다:
function UserNameDisplay() {
const { data } = useCurrentUserQuery()
return <div>User: {data.userName}</div>
}
function UserNameDisplay() {
const { data } = useCurrentUserQuery()
return <div>User: {data.userName}</div>
}
그러나 TypeScript는 이를 허용하지 않을 것입니다. data가 정의되지 않았을 수 있기 때문입니다. 하지만 우리는 더 잘 알고 있습니다. 우리의 상황에서는 UserNameDisplay가 렌더링될 때 쿼리가 이미 트리 상위에서 시작되었을 것이기 때문에 data가 정의되지 않을 리 없습니다.
이는 딜레마입니다. TypeScript를 무시하고 data!.userName을 사용해야 할까요? 안전하게 data?.userName을 사용해야 할까요? (이 경우에는 가능하지만 다른 상황에서는 쉽지 않을 수 있습니다) 아니면 if (!data) return null과 같은 가드를 추가해야 할까요? 또는 useCurrentUserQuery를 사용하는 25곳 모두에 제대로 된 로딩 및 에러 처리를 추가해야 할까요?
솔직히 말해서, 이 모든 방법이 최적이 아닌 것 같습니다. "절대 일어날 수 없는" (적어도 현재 내 지식으로는) 검사로 코드베이스를 어지럽히고 싶지 않습니다. 하지만 TypeScript를 무시하고 싶지도 않습니다. 왜냐하면 (늘 그렇듯이) TypeScript가 맞기 때문입니다.
암묵적 의존성
우리의 문제는 '암묵적 의존성'에서 비롯됩니다. 이는 코드상에서는 보이지 않고, 우리 머릿속에만 존재하는 의존성, 즉 애플리케이션 구조에 대한 우리의 지식에만 존재하는 의존성입니다.
useCurrentUserQuery를 데이터가 정의되지 않았을 가능성을 체크하지 않고 안전하게 호출할 수 있다는 것을 우리는 알고 있지만, 어떤 정적 분석도 이를 검증할 수 없습니다. 우리의 동료들도 이를 모를 수 있습니다. 심지어 저 자신도 3개월 후에는 이를 잊어버릴 수 있습니다.
가장 위험한 점은 지금은 맞을지 몰라도 나중에는 틀릴 수 있다는 것입니다. 앱의 다른 곳에 UserNameDisplay의 또 다른 인스턴스를 렌더링하기로 결정할 수 있습니다. 그곳에서는 캐시에 사용자 데이터가 없거나, 다른 페이지를 먼저 방문했을 때만 조건부로 캐시에 사용자 데이터가 있을 수 있습니다.
이는 <ProductTable> 컴포넌트와는 정반대입니다. 변화에 강한 것이 아니라 리팩토링에 취약해집니다. 우리는 일부 관련 없어 보이는 컴포넌트를 옮기는 것만으로 UserNameDisplay 컴포넌트가 깨질 것이라고 예상하지 못할 것입니다.
명시적으로 만들기
해결책은 물론 의존성을 '명시적'으로 만드는 것입니다. 이를 위한 최고의 방법은 React Context를 사용하는 것입니다:
React Context
React Context에 대해서는 꽤 많은 오해가 있습니다. 명확히 말씀드리자면: 아니요, React Context는 상태 관리자가 아닙니다. useState나 useReducer와 결합하면 상태 관리를 위한 좋은 해결책처럼 보일 수 있지만, 솔직히 말해서 저는 이런 접근 방식을 좋아하지 않습니다. 다음과 같은 상황에 너무 많이 당했기 때문입니다:
@TkDodo
🕵️ 이번 주에 우리는 useState + context를 zustand로 옮겨서 큰 성능 문제를 해결했습니다. 코드 양은 동일했고, 라이브러리 크기는 1kb 미만입니다.
⚛️ 상태 관리에 context를 사용하지 마세요. context는 의존성 주입용으로만 사용하세요. 적절한 도구를 사용하는 것이 중요합니다!
zustand.surge.sh
따라서 전용 도구를 사용하는 것이 더 좋을 것입니다. Redux의 메인테이너이자 매우 긴 블로그 포스트의 작성자인 Mark Erikson은 이 주제에 대해 좋은 글을 썼습니다: 블로그 답변: React Context가 "상태 관리" 도구가 아닌 이유 (그리고 왜 Redux를 대체하지 않는지).
제 트윗에서 이미 언급했듯이, React Context는 '의존성 주입' 도구입니다. 컴포넌트가 작동하는 데 필요한 "것들"을 정의할 수 있게 해주고, 그 정보를 제공하는 것은 부모의 책임입니다.
이는 개념적으로 프롭 드릴링과 같습니다. 프롭 드릴링은 여러 계층을 통해 프롭을 전달하는 과정입니다. Context를 사용하면 같은 일을 할 수 있지만, 몇 개의 계층을 건너뛸 수 있습니다:
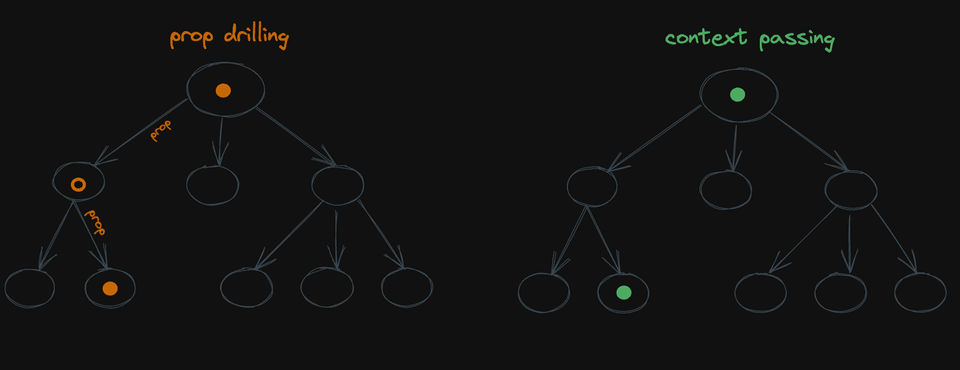
Context를 사용하면 중간 단계를 건너뛸 수 있습니다. useCurrentUserQuery 예제에서는 데이터 가용성 검사를 건너뛰고 싶은 모든 컴포넌트에서 useCurrentUserQuery를 직접 읽는 대신, React Context에서 읽을 수 있게 도와줍니다. 그리고 이 context는 실제로 첫 번째 검사를 수행하는 부모에 의해 채워질 것입니다:
const CurrentUserContext = React.createContext<User | null>(null)
export const useCurrentUserContext = () => {
return React.useContext(CurrentUserContext)
}
export const CurrentUserContextProvider = ({
children,
}: {
children: React.ReactNode
}) => {
const currentUserQuery = useCurrentUserQuery()
if (currentUserQuery.isLoading) {
return <SkeletonLoader />
}
if (currentUserQuery.isError) {
return <ErrorMessage error={currentUserQuery.error} />
}
return (
<CurrentUserContext.Provider value={currentUserQuery.data}>
{children}
</CurrentUserContext.Provider>
)
}
const CurrentUserContext = React.createContext<User | null>(null)
export const useCurrentUserContext = () => {
return React.useContext(CurrentUserContext)
}
export const CurrentUserContextProvider = ({
children,
}: {
children: React.ReactNode
}) => {
const currentUserQuery = useCurrentUserQuery()
if (currentUserQuery.isLoading) {
return <SkeletonLoader />
}
if (currentUserQuery.isError) {
return <ErrorMessage error={currentUserQuery.error} />
}
return (
<CurrentUserContext.Provider value={currentUserQuery.data}>
{children}
</CurrentUserContext.Provider>
)
}
여기서는 currentUserQuery를 가져와 결과 데이터를 React Context에 넣습니다(로딩 상태와 에러 상태를 미리 제거한 후). 그러면 자식 컴포넌트에서 안전하게 이 context를 읽을 수 있습니다. 예를 들어 UserNameDisplay 컴포넌트에서는 다음과 같이 사용할 수 있습니다:
function UserNameDisplay() {
const data = useCurrentUserContext()
return <div>User: {data.username}</div>
}
function UserNameDisplay() {
const data = useCurrentUserContext()
return <div>User: {data.username}</div>
}
이렇게 하면 암묵적 의존성(데이터가 트리 상위에서 이미 가져와졌다는 것을 우리가 알고 있다는 점)을 명시적으로 만들었습니다. UserNameDisplay를 볼 때마다 CurrentUserContextProvider에서 데이터를 제공받아야 한다는 것을 알 수 있습니다. 이는 리팩토링 시 염두에 둘 수 있는 사항입니다. 프로바이더가 렌더링되는 위치를 변경하면 이 context를 사용하는 모든 자식에 영향을 미친다는 것을 알 수 있습니다. 이는 컴포넌트가 단순히 쿼리를 사용할 때는 알 수 없는 정보입니다. 쿼리는 보통 앱 전체에서 전역적이며, 데이터가 존재할 수도 있고 존재하지 않을 수도 있기 때문입니다.
TypeScript 만족시키기
TypeScript는 여전히 이를 완전히 만족스럽게 여기지 않을 것입니다. React Context는 프로바이더 없이도 작동하도록 설계되었기 때문에, 프로바이더가 없을 때는 Context의 기본값(우리의 경우 null)을 제공합니다. 우리는 프로바이더 외부에서 useCurrentUserContext가 작동하는 상황을 원하지 않으므로, 커스텀 훅에 불변 조건을 추가할 수 있습니다:
export const useCurrentUserContext = () => {
const currentUser = React.useContext(CurrentUserContext)
if (!currentUser) {
throw new Error('CurrentUserContext: No value provided')
}
return currentUser
}
export const useCurrentUserContext = () => {
const currentUser = React.useContext(CurrentUserContext)
if (!currentUser) {
throw new Error('CurrentUserContext: No value provided')
}
return currentUser
}
이 방법을 사용하면 실수로 잘못된 위치에서 useCurrentUserContext에 접근할 경우 빠르게 실패하고 명확한 오류 메시지를 제공할 수 있습니다. 이렇게 하면 TypeScript는 우리의 커스텀 훅 값을 User 타입으로 추론하므로 안전하게 사용하고 속성에 접근할 수 있습니다.
상태 동기화
이런 생각이 들 수 있습니다: "이것은 '상태 동기화'가 아닌가요? React Query에서 값을 복사해서 다른 상태 분배 방식에 넣는 것 아닌가요?"
답은 "아니오"입니다! 단일 진실 소스는 여전히 쿼리입니다. 프로바이더를 제외하고는 context 값을 변경할 방법이 없으며, 프로바이더는 항상 쿼리가 가진 최신 데이터를 반영할 것입니다. 여기서는 아무것도 복사되지 않으며, 동기화가 어긋날 수 없습니다. React Query에서 data를 자식 컴포넌트에 프롭으로 전달하는 것도 "상태 동기화"가 아니며, context가 프롭 드릴링과 유사하므로 이 역시 "상태 동기화"가 아닙니다.
요청 폭포
어떤 기술에도 단점은 있기 마련이며, 이 기술도 예외는 아닙니다. 특히 네트워크 폭포를 만들 수 있습니다. 컴포넌트 트리가 프로바이더에서 렌더링을 멈추기(일시 중단) 때문에 자식 컴포넌트가 렌더링되지 않아 관련 없는 네트워크 요청도 시작할 수 없기 때문입니다.
저는 이 접근 방식을 주로 하위 트리에 '필수적인' 데이터에 대해 고려할 것입니다. 사용자 정보가 좋은 예시입니다. 그 데이터 없이는 무엇을 렌더링해야 할지 모를 수 있기 때문입니다.
서스펜스
서스펜스에 대해 말하자면: 네, React 서스펜스로도 비슷한 아키텍처를 구현할 수 있습니다. 그리고 네, 같은 단점이 있습니다: 잠재적인 요청 폭포입니다. 이에 대해서는 이미 #17: 쿼리 캐시 시드하기에서 다룬 바 있습니다.
한 가지 문제는 현재 주요 버전(v4)에서 쿼리에 suspense: true를 사용해도 data의 타입을 좁히지 않는다는 점입니다. 쿼리를 비활성화하고 실행하지 않을 방법이 여전히 있기 때문입니다.
그러나 v5부터는 명시적인 useSuspenseQuery 훅이 있어, 컴포넌트가 렌더링되면 데이터가 반드시 정의되어 있음을 보장합니다. 이를 통해 다음과 같이 할 수 있습니다:
function UserNameDisplay() {
const { data } = useSuspenseQuery(...)
return <div>User: {data.username}</div>
}
function UserNameDisplay() {
const { data } = useSuspenseQuery(...)
return <div>User: {data.username}</div>
}
그러면 TypeScript도 만족할 것입니다. 🎉
YouTube 영상









